
Les outils de l'intelligence artificielle se développent et soulèvent des questions fondamentales sur le processus de recherche. Nous avons demandé à deux bibliothécaires de l'Université de Sherbrooke de partager leurs réflexions autour de la création d'un guide institutionnel encadrant l'utilisation de ces outils en milieu universitaire.
Les intelligences artificielles entrent à l’UdS
À la fin de 2022, les intelligences artificielles génératives (IAg) deviennent largement accessibles par des agents conversationnels conviviaux sur le Web, au lieu d’être réservées à une poignée d’entreprises fortunées ou de centres de recherche. L’explosion du nombre d'utilisateurs réguliers de ces outils, plus de 100 millions après deux mois d’existence pour ChatGPT1, a surpris le milieu universitaire. Au début fascinés par le fonctionnement des IAg, qui semblait presque magique, les membres de la communauté ont peu à peu commencé à s’y intéresser sérieusement.
Dans le contexte universitaire, les IAg bousculent les pratiques d’évaluation, le mode d’acquisition des compétences informationnelles ainsi que les méthodes de recherche. Les bibliothèques se sont mises à recevoir des questions d’un type inédit : Que faire quand des étudiant·es se présentent avec des références... forgées de toutes pièces par ChatGPT et consorts? Est-ce du plagiat? Sous quelle forme présenter les citations si on utilise du texte généré? Doit-on mettre ChatGPT comme auteur? Etc.
Dans le contexte universitaire, les [intelligences artificielles génératives] bousculent les pratiques d’évaluation, le mode d’acquisition des compétences informationnelles ainsi que les méthodes de recherche.
La position institutionnelle
En mars 2023, le Service de soutien à la formation (SSF) de l’Université de Sherbrooke, mandaté par la direction, a contribué à la création de l’énoncé de principe institutionnel en cette matière, lequel privilégie la familiarisation avec les IAg et l’intégration progressive dans les cursus plutôt que l'interdiction. Il a également participé à l’amendement du règlement des études. Dès juin 2023, le Service des bibliothèques et archives (SBA) a intégré officiellement le groupe de travail restreint « Apprivoiser les IA » et la communauté de pratique créés par le SSF. Les deux services travaillent ensemble sur de nombreux projets, dont la création de balises servant d’outils pour transmettre aux étudiants et étudiantes la position de leur enseignant·e dans le cadre des formations et des évaluations. Parallèlement, le SBA a mis les bouchées doubles pour développer de nouvelles formations de sensibilisation à l’intention des personnes étudiantes sur l’éthique, la protection des renseignements personnels et les compétences informationnelles. La collaboration entre les deux services permet d’arrimer le message tant du côté du personnel enseignant que de la communauté étudiante.
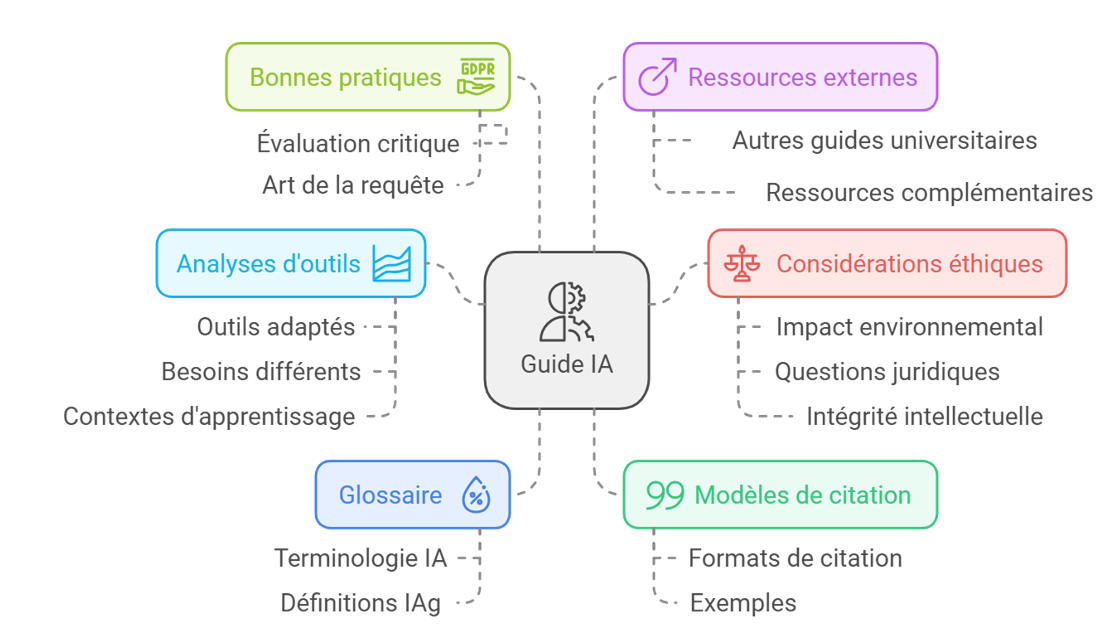
Un guide pratique pour la communauté
En janvier 2024, les deux bibliothécaires et deux techniciens spécialisés en IA au SBA, à l'instar de nombreux confrères et consœurs d’autres universités, ont publié un guide visant à aiguiller la communauté quant à l’utilisation éthique et efficace des IA, et en particulier des IAg. Ce guide transdisciplinaire comprend notamment un glossaire, des modèles de citations, des exemples de bonnes pratiques de rédactique (« l’art de la requête »; accueillons comme il le mérite ce néologisme de l’OQLF) et des analyses d'outils d’IA adaptés à différents besoins, niveaux et contextes d’apprentissage. On y aborde également les aspects éthiques, sociaux et juridiques liés à l'utilisation des IAg. Enfin, le guide propose une riche sélection de ressources externes triées sur le volet.
Les IA en recherche
Les outils d’IA utiles en recherche sont multiples et variés. En tant que bibliothécaires, nous tenons à informer la communauté de leur potentiel en fonction du contexte, de leurs limites et des enjeux éthiques, sociaux ou environnementaux qu’ils soulèvent. Mais surtout, notre rôle est d’outiller la communauté de recherche pour qu’elle fasse des choix éclairés lorsqu’il s’agit de tirer parti de ces technologies (que je n’oserais pas qualifier de « nouvelles »!) en connaissance de cause.
La littéracie informationnelle et les IA
Nous devons trouver l’équilibre entre un discours alarmiste et frileux, d’une part, et l’enthousiasme irrationnel pour la nouveauté, d’autre part. Pour ce faire, nous nous appuyons sur les données de la recherche, de même que sur les travaux menés notamment par deux consœurs pionnières en matière de recherche sur l’utilisation des IA en sciences de l’information : Sandy Hervieux et Amanda Weathley, bibliothécaires à l’Université McGill. Ces deux chercheuses ont développé ROBOT, une grille d’évaluation des outils d’IA sous licence CC-BY. Le service des bibliothèques de l’ÉTS a francisé ROBOT et l’a adapté en format Genially, toujours en CC-BY, ce qui nous a permis de l’intégrer à notre guide. Ce « Robot test » est l’outil à utiliser lorsqu’il s’agit de choisir une IA pour une tâche donnée.
Les IA en soutien à la revue de littérature…
Le succès fulgurant de ChatGPT a donné un nouveau souffle à la recherche sur le rôle des IA en soutien au processus de recherche, notamment dans l’exercice méthodologique. Plusieurs auteur·trices ont examiné le potentiel d’efficacité de divers outils. Si tous et toutes s’entendent pour affirmer qu’aucune IA n’est à même de remplacer l’humain pour les tâches cognitives de haut niveau (raisonnement général, sélection des études, compréhension de texte, évaluation critique), plusieurs reconnaissent toutefois l’intérêt d’utiliser les algorithmes pour automatiser les tâches répétitives et administratives (recherche d’études, mise en forme de références, rédaction d’un résumé, reformulation, manipulation de données…), ou encore, pour générer des idées à l’étape de la conception. De fait, les ChatGPT de ce monde, en tant qu’agents conversationnels, sont des outils idéaux pour retourner une question de recherche dans tous les sens, explorer les angles possibles, générer des sous-questions et obtenir un premier aperçu des vides existants dans la littérature. D’où l’importance, d’ailleurs, d’apprendre à maîtriser l’art de la requête pour ce genre de tâche très langagière.
Si tous et toutes s’entendent pour affirmer qu’aucune IA n’est à même de remplacer l’humain pour les tâches cognitives de haut niveau [...], plusieurs reconnaissent toutefois l’intérêt d’utiliser les algorithmes pour automatiser les tâches répétitives et administratives [...], ou encore, pour générer des idées à l’étape de la conception.
Dans son excellent article paru à la fin août 2024, Molopa2 s’est penché sur l’évaluation systématique d’outils d’IA à différentes étapes de la recherche. Il compare les outils selon leurs fonctionnalités, les corpus utilisés (en libre accès ou non?) et la qualité des résultats. Il conclut à la grande efficacité des outils suivants : ChatGPT et Bard (aujourd’hui Gemini) pour la conception de la recherche et la structuration (rédaction) du texte; Google Scholar et Research Rabbit en soutien à la composition de la revue de littérature; Lateral.io pour l’analyse des données. Fait intéressant, on oublie trop souvent que Google Scholar, par ses algorithmes obscurs d’information retrieval enrichis d’apprentissage automatique (très probablement, bien que les algorithmes soient tenus secrets par l’entreprise), se qualifie sans doute comme un outil d’IA, mais au sens faible du terme.
Malgré les prouesses techniques de nos nouveaux assistants, Molopa insiste lourdement sur l’importance de la synergie humain-machine, considérant notamment que tout contenu à visée scientifique généré par une IAg doit faire l’objet d’une validation humaine.
…et aux autres méthodologies
Il y aurait long à dire encore sur les IA non génératives utilisées depuis des décennies en analyse de données qualitatives (traitement automatique des langues, catégorisation automatique, analyse de discours, représentation des connaissances…) et quantitatives (analyse statistique), qui ont fait leurs preuves et méritent de survivre au raz-de-marée des IAg. Votre université possède probablement un ou plusieurs services de soutien à l’analyse statistique ou textuelle, qui utilisent des technologies d’IA moins connues, mais plus appropriées que ChatGPT, pour accomplir une tâche spécialisée comme l’extraction de concepts.
Cela étant, nous nous contenterons ici de dire quelques mots sur la tentation d’utiliser les IAg pour « accélérer » le processus fastidieux, mais essentiel, de conduite d’une méta-analyse ou d’une revue systématique. Ces méthodologies de recherche très particulières, et de plus en plus populaires en raison de l’accroissement vertigineux du corpus d’études primaires et de données disponibles, ont souvent pour objectif de soutenir la prise de décision publique dans les domaines névralgiques de la société comme la santé ou l’environnement. Pour cette raison, les méthodologies qui sous-tendent ce type de synthèses de connaissances sont extrêmement précises et rigoureuses : on exige une exhaustivité aussi parfaite que possible, une sélection des études par deux réviseur·es, des critères d’inclusion prédéfinis et des hypothèses déposées avant la collecte des données, par exemple. On dit souvent que la qualité d’une revue systématique dépend de la qualité de la stratégie de recherche documentaire, laquelle implique une recherche terminologique approfondie.
Or, il peut être tentant d’utiliser les IAg pour prendre des raccourcis durant le long parcours que représente la conduite d’une synthèse des connaissances, par exemple au moment de la sélection des études, de l’extraction d’information ou de la rédaction de l’article. Dans tous ces cas, le fait de déléguer l’intelligence à la machine peut faire dérailler tout le processus, et induire des erreurs ou omissions qui n’ont pas leur place dans le cadre d’une revue systématique.
On dit souvent que la qualité d’une revue systématique dépend de la qualité de la stratégie de recherche documentaire, laquelle implique une recherche terminologique approfondie. [...] le fait de déléguer l’intelligence à la machine peut faire dérailler tout le processus, et induire des erreurs ou omissions qui n’ont pas leur place dans le cadre d’une revue systématique.
La réputation de la science
Dans les deux dernières années, on a beaucoup parlé des enjeux de collecte d’informations personnelles ou sensibles, de propriété intellectuelle, de validité de l’information et des biais induits par les grands modèles de langage. Cependant, on a un peu moins mis l’accent sur les dérives déjà en cours dans le monde de l’édition scientifique, les images frauduleuses générées par les IAg, les manuscrits soumis avec des résidus de langage « GPTesques » – « Je suis une intelligence artificielle, je ne peux pas répondre à cette question » – qui persistent dans de nombreux manuscrits soumis aux éditeurs scientifiques. On ne parle pas encore assez non plus de la nécessaire créativité en recherche, et des risques engendrés à cet égard par l’utilisation abusive d’une IAg, par exemple, pour rédiger un premier jet.
Il sera intéressant de suivre l’évolution des politiques des grands éditeurs (à l’instar d’Elsevier) en matière d’utilisation des IA dans l’édition scientifique. En attendant, il nous revient, chercheur·euses et futurs membres de la communauté de recherche, de faire un usage réfléchi de technologies qui, quoique puissantes, comportent des risques.
Perspectives et évolutions futures
L’avenir sera encore riche en apprentissages et en évolutions pour les communautés de recherche. Ce qui se profile à l’horizon, par exemple, c’est l’implantation de modules d’IA à même les banques de données scientifiques, des modèles plus modestes et plus spécialisés dans certains domaines, ou encore, ceux, pré-entraînés, que l’on exécute sur un poste informatique conventionnel hors ligne à l’aide de codes sources sous licence ouverte (comme ceux que l’on peut trouver dans des communautés telle Hugging Face). Ces solutions de rechange à nos grands modèles de langage en ligne, dévastateurs pour l’environnement, de même que l’éducation sur le fonctionnement de tels outils, pourraient donner lieu à des usages plus responsables et durables des IAg.
Quoi qu’il en soit, partout au Québec, au Canada et dans le monde, des groupes de travail et des communautés de pratique se forment pour continuer à développer et améliorer des outils et des ressources afin d’encourager une utilisation éthique et critique des IAg dans les salles de classe et dans le cadre des travaux de recherche universitaire.
En attendant, il nous revient, chercheur·euses et futurs membres de la communauté de recherche, de faire un usage réfléchi de technologies qui, quoique puissantes, comportent des risques.
Références consultées
Alshami, A., Elsayed, M., Ali, E., Eltoukhy, A. E. E., & Zayed, T. (2023). Harnessing the Power of ChatGPT for Automating Systematic Review Process: Methodology, Case Study, Limitations, and Future Directions. Systems, 11(7), 351. https://doi.org/10.3390/systems11070351Haman, M., & Školník, M. (2023). Using ChatGPT to conduct a literature review. Accountability in Research, 13. https://doi.org/10.1080/08989621.2023.2185514
Hervieux, S. & Wheatley, A. (2020). The ROBOT test [Evaluation tool]. The LibrAIry. https://thelibrairy.wordpress.com/2020/03/11/the-robot-test
Hu, K. (2023, 2 février). ChatGPT sets record for fastest-growing user base - analyst note. Reuters. https://www.reuters.com/technology/chatgpt-sets-record-fastest-growing-user-base-analyst-note-2023-02-01/
Khraisha, Q., Put, S., Kappenberg, J., Warraitch, A., & Hadfield, K. (2023). Can large language models replace humans in the systematic review process? Evaluating GPT-4’s efficacy in screening and extracting data from peer-reviewed and grey literature in multiple languages (No. arXiv:2310.17526; Version 2). arXiv. http://arxiv.org/abs/2310.17526
Mahuli, S. A., Rai, A., Mahuli, A. V., & Kumar, A. (2023). Application ChatGPT in conducting systematic reviews and meta-analyses. British Dental Journal, 235(2), Article 2. https://doi.org/10.1038/s41415-023-6132-y
Molopa, S. T. (2024). Artificial intelligence-based literature review adaptation. South African Journal of Libraries and Information Science, 90(2), Article 2. https://doi.org/10.7553/90-1-2390
Qureshi, R., Shaughnessy, D., Gill, K. A. R., Robinson, K. A., Li, T., & Agai, E. (2023). Are ChatGPT and large language models “the answer” to bringing us closer to systematic review automation? Systematic Reviews, 12(1), 72. https://doi.org/10.1186/s13643-023-02243-z
Rahman, M. M., Terano, H. J., Rahman, M. N., Salamzadeh, A., & Rahaman, M. S. (2023). ChatGPT and Academic Research : A Review and Recommendations Based on Practical Examples (SSRN Scholarly Paper No. 4407462). https://papers.ssrn.com/abstract=4407462
Syriani, E., David, I., & Kumar, G. (2023). Assessing the Ability of ChatGPT to Screen Articles for Systematic Reviews (No. arXiv:2307.06464). arXiv. https://doi.org/10.48550/arXiv.2307.06464
Tools such as ChatGPT threaten transparent science; here are our ground rules for their use. (2023). Nature, 613(7945), 612‑612. https://doi.org/10.1038/d41586-023-00191-1
Wang, S., Scells, H., Koopman, B., & Zuccon, G. (2023). Can ChatGPT Write a Good Boolean Query for Systematic Review Literature Search? (No. arXiv:2302.03495). arXiv. https://doi.org/10.48550/arXiv.2302.03495
- 1
Hu, K. (2023, 2 février). ChatGPT sets record for fastest-growing user base - analyst note. Reuters. https://www.reuters.com/technology/chatgpt-sets-record-fastest-growing-user-base-analyst-note-2023-02-01/
- 2
Molopa, S. T. (2024). Artificial intelligence-based literature review adaptation. South African Journal of Libraries and Information Science, 90(2), Article 2. https://doi.org/10.7553/90-1-2390
- Myriam Beaudet et Mireille Léger-Rousseau
Université de Sherbrooke
Myriam Beaudet est bibliothécaire au Service des bibliothèques et archives de l’Université de Sherbrooke depuis 2011, où elle apporte depuis quelques années son soutien aux disciplines liées à la Faculté d'éducation. Son domaine d’expertise a évolué des ressources éducatives libres (REL) vers l’intelligence artificielle en sciences de l'information, en réponse à l'essor et à la démocratisation de l'intelligence artificielle générative (IAg). Elle a rapidement intégré le groupe de travail « Apprivoiser les IA », établi par le Service de soutien à la formation, pour répondre aux défis que représente cette transformation.
Mireille Léger-Rousseau est bibliothécaire à l’Université de Sherbrooke depuis 2019. Ce parcours fait suite à une carrière de linguiste sémanticienne qui l’a menée, notamment, à contribuer à des systèmes de représentation des connaissances et de traitement automatique des langues pour des applications d’intelligence artificielle. Diplômée de l’Université de Montréal en linguistique (1er cycle) et en sciences de l’information (2e cycle) à l’École de bibliothéconomie et des sciences de l’information (EBSI), elle s’intéresse à la gestion des données de recherche et à l’intégration de l’intelligence artificielle en contexte de recherche.
Vous aimez cet article?
Soutenez l’importance de la recherche en devenant membre de l’Acfas.
Devenir membre


Commentaires

Articles suggérés
Infolettre